Linear Operators
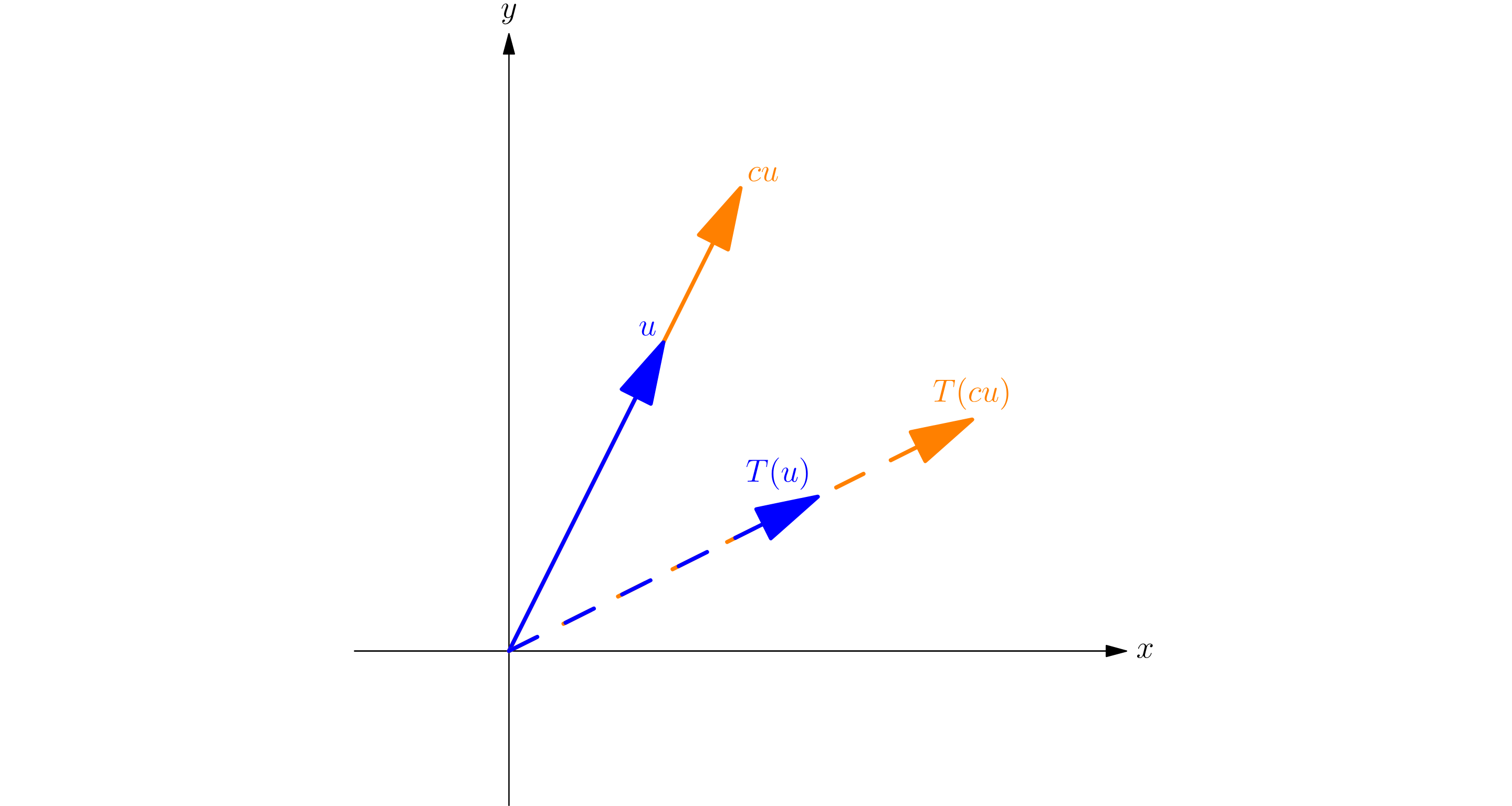
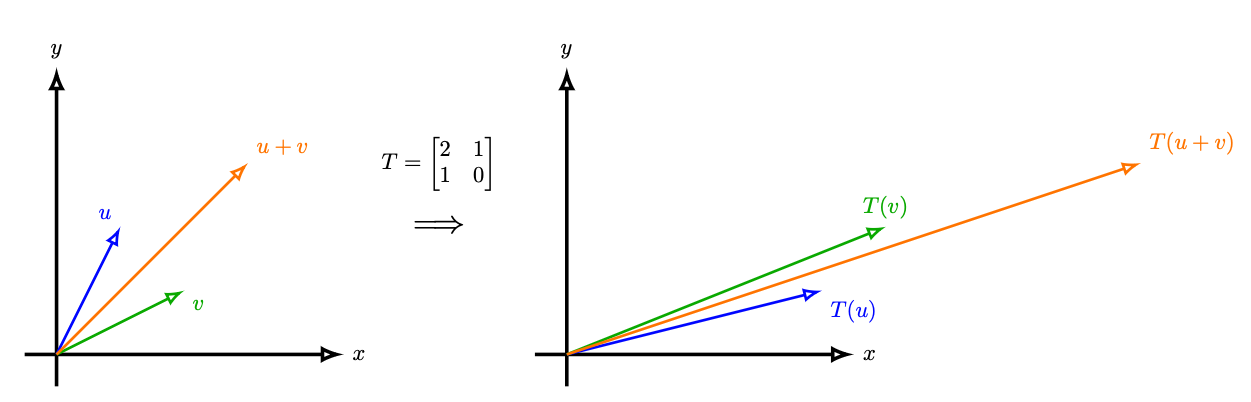
A linear operator \(L\) is just anything that satisfies \(L(ax+by)=aL(x)+bL(y)\), for constants \(a\) and \(b\), and where addition and multiplication are defined. In other words, it is additive, and you can pull out constants from the inside.
Matrices are where you probably saw this. If you transform a vector \(x\) by multiplying it with \(A\), do the same for a vector \(y\), and add the two new vectors, it’s the same as just adding them first and then transforming them. Also, if you scale \(x\) and \(y\) by some constants, it doesn’t matter if you did it before or after the transformation.
Derivatives As Linear Operators
Do you remember the sum and product rules of single-variable derivatives?
\(\frac{d}{dx} (af(x)) = a \frac{d}{dx} f(x)\) \(\frac{d}{dx} (f(x) + g(x)) = \frac{d}{dx} f(x) + \frac{d}{dx} g(x)\)
Wait, what??? Differentiation is also a linear operator on functions??? Now you realize how cool generalizing stuff is.
Hold on. Is \(y=mx+b\) linear on \(x\), for \(b \neq 0\)? The answer, surprisingly, is no. \(m(x_1+x_2)+b \neq (mx_1+b)+(mx_2+b)\). Linear, in this the context of this blog post, doesn’t necessarily mean the function is a line, but rather that the function behaves like a linear operator, which are typically different things. However, don’t think this form of function isn’t useful outside of 7th grade - when generalized to matrices, these can be very useful in AI.
Slight Tangent on Affine Transformations
Transformations of the form \(y=mx+b\) aren’t linear, but instead affine. Obviously not everything has to be a scalar, but instead can be about vectors and matrices where you have \(f(\vec{v}) = A \vec{v} + \vec{b}\) for some matrix \(A\). Where are affine transformations actually used?
A really common example is to get from one layer of a neural network to another, right before the activation function (more on that in the blog about neural networks). You multiply the vector of inputs in one layer by the matrix of weights and add to that the vector of biases to get the next layer pre-activation.
To be continued
Well, this was not very abstract… yet. In the following parts, we will actually make derivatives more abstract, but this one was just the setup. So, don’t leave just yet.